From below table as input, we are trying to add a column from Address using geopy Nominatim, in order to calculate distance with user input coordinate to sample only dataset within certain radius, say 5 miles.
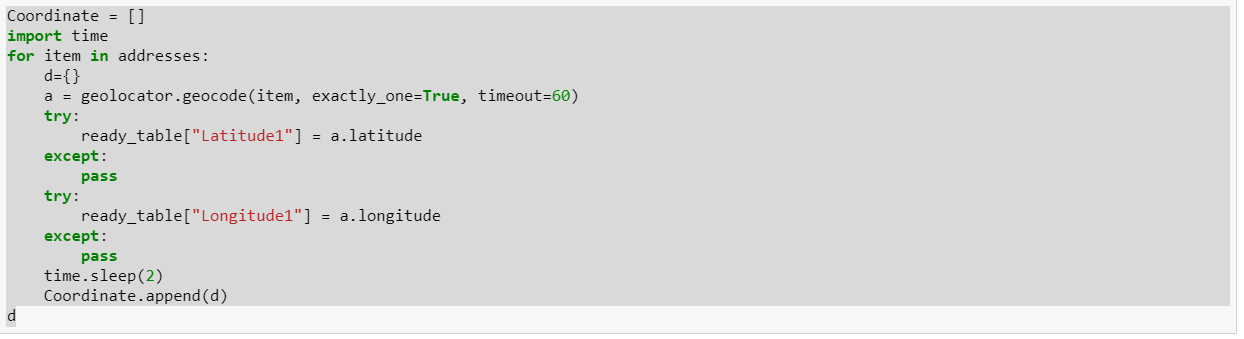
From below code => we get all coordinates of 487 rows from original 501 rows. We deleted 14 addresses that can’t be converted, but had trouble appending this data (with different length than 501 rows) to the table.
One option is to define a function that returns np.nan for rows that are incomplete and use DataFrame.apply.
import numpy as np
import pandas as pd
from geopy import GoogleV3
api_key = 'AIzaSyDNqc0tWzXHx_wIp1w75-XTcCk4BSphB5w'
geocode = GoogleV3(api_key).geocode
def get_location(row):
address = row['address']
location = geocode(address)
if location is None:
return np.nan
row['longitude'] = location.longitude
row['latitude'] = location.latitude
return row
address_table = pd.DataFrame([
['415 E 71st St, New York, NY'],
['abcdefg'],
['65-60 Kissena Blvd, Flushing, NY'],
], columns=['address'])
geolocated_table = address_table.apply(get_location, axis=1)
clean_table = geolocated_table.dropna(subset=['longitude', 'latitude'])
Another option is to define a pandas.Series where you specify only the row indices that have valid values.
import pandas as pd
from shapely.geometry import Point
d = {}
for index, row in address_table.iterrows():
address = row['address']
location = geocode(address)
if not location:
continue
geometry = Point(location.longitude, location.latitude)
d[index] = geometry.wkt
address_table['wkt'] = pd.Series(d)